data(house.selling.price.2)summary(lm(P ~ ., data = house.selling.price.2))
Call:
lm(formula = P ~ ., data = house.selling.price.2)
Residuals:
Min 1Q Median 3Q Max
-36.212 -9.546 1.277 9.406 71.953
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -41.795 12.104 -3.453 0.000855 ***
S 64.761 5.630 11.504 < 2e-16 ***
Be -2.766 3.960 -0.698 0.486763
Ba 19.203 5.650 3.399 0.001019 **
New 18.984 3.873 4.902 4.3e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 16.36 on 88 degrees of freedom
Multiple R-squared: 0.8689, Adjusted R-squared: 0.8629
F-statistic: 145.8 on 4 and 88 DF, p-value: < 2.2e-16
Part A
Question: For backward elimination, which variable would be deleted first? Why?
Answer: For backward elimination, the first variable to be deleted would be the beds variable, as it is the weakest indicator with the highest p-value (0.486763) in the regression analysis.
Part B
Question: For forward selection, which variable would be added first? Why?
Answer: For forward selection, the first variable to be added would be size, as it has the highest t-value (11.504) in the regression analysis.
Part C
Question: Why do you think that BEDS has such a large P-value in the multiple regression model, even though it has a substantial correlation with PRICE?
Answer: I think that the beds variable is not statistically significant, which has little to do with the correlation (correlation does not equal causation). There could be another, stronger indicator that is influencing the high correlation with price, such as the size of the house.
Part D
Question: Using software with these four predictors, find the model that would be selected using each criterion:
Part 1: R2
Code
m1 <-lm(P ~ S, house.selling.price.2)stargazer(m1, type ='text')
Error in stargazer(m1, type = "text"): could not find function "stargazer"
Code
m2 <-lm(P ~ Be, house.selling.price.2)stargazer(m2, type ='text')
Error in stargazer(m2, type = "text"): could not find function "stargazer"
Code
m3 <-lm(P ~ Ba, house.selling.price.2)stargazer(m3, type ='text')
Error in stargazer(m3, type = "text"): could not find function "stargazer"
Code
m4 <-lm(P ~ New, house.selling.price.2)stargazer(m4, type ='text')
Error in stargazer(m4, type = "text"): could not find function "stargazer"
Code
m5 <-lm(P~., house.selling.price.2)stargazer(m5, type ='text')
Error in stargazer(m5, type = "text"): could not find function "stargazer"
Code
m6 <-lm(P~.-Be, house.selling.price.2)stargazer(m6, type ='text')
Error in stargazer(m6, type = "text"): could not find function "stargazer"
Answer: The model that I prefer would be m6, which includes all variables but the beds variable. It was the best fit model in most of the tests. A second choice would be m5, which includes all variables, as it also performed similarly to m6.
Question 2
Part A
Fit a multiple regression model with the Volume as the outcome and Girth and Height as the explanatory variables.
Code
tree <-lm(Volume ~ Girth + Height, data=trees)tree
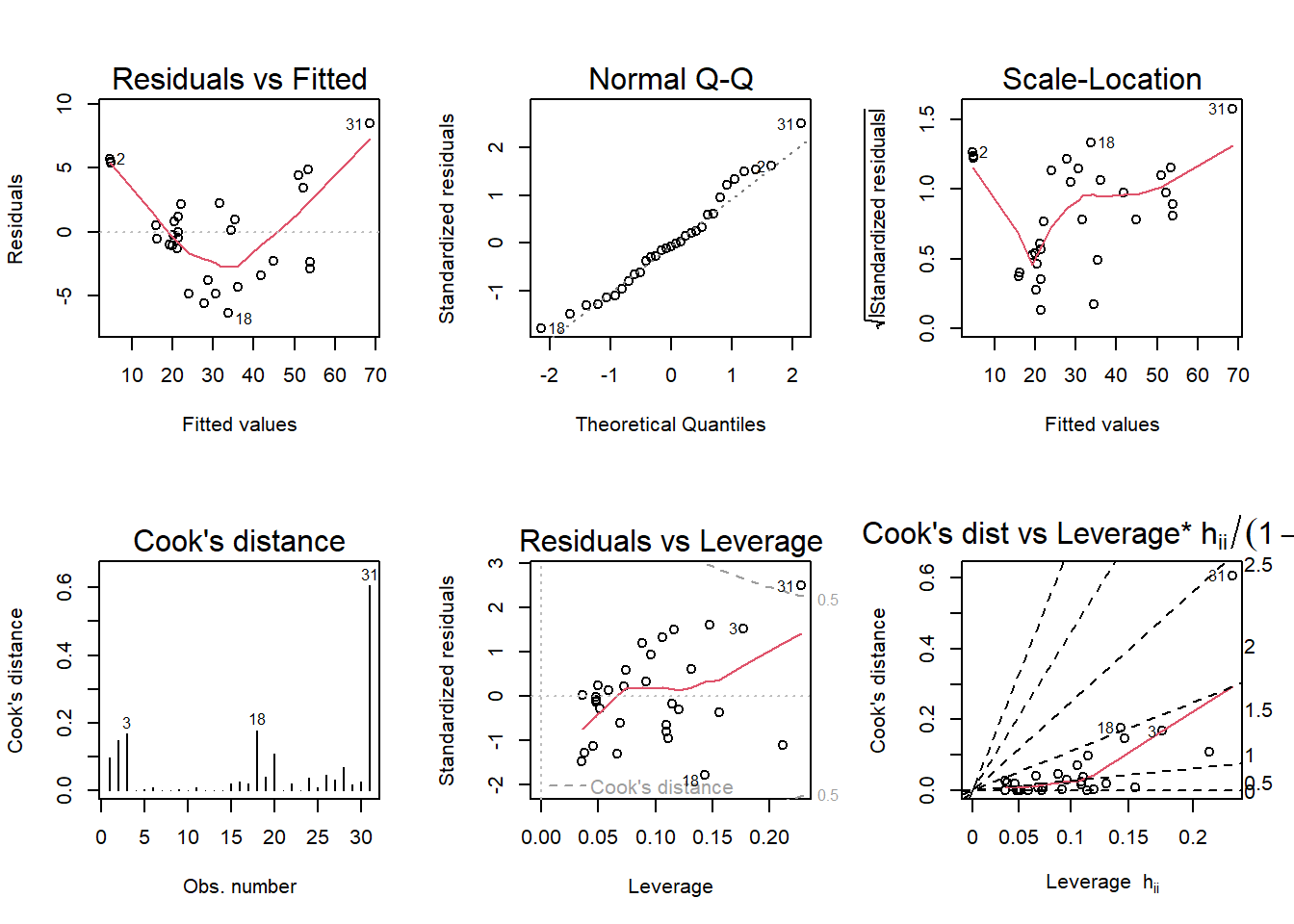
Run regression diagnostic plots on the model. Based on the plots, do you think any of the regression assumptions is violated?
Code
par(mfrow =c(2,3)); plot(tree, which =1:6)
Answer: In the first plot, residuals vs fitted, the assumption of linearity is violated as the line is a curved line rather than linear. The other plot that has a violation is the scale-location plot, as it is not a horizontal line, but rather, interestingly skewed.
Question 3
Part A
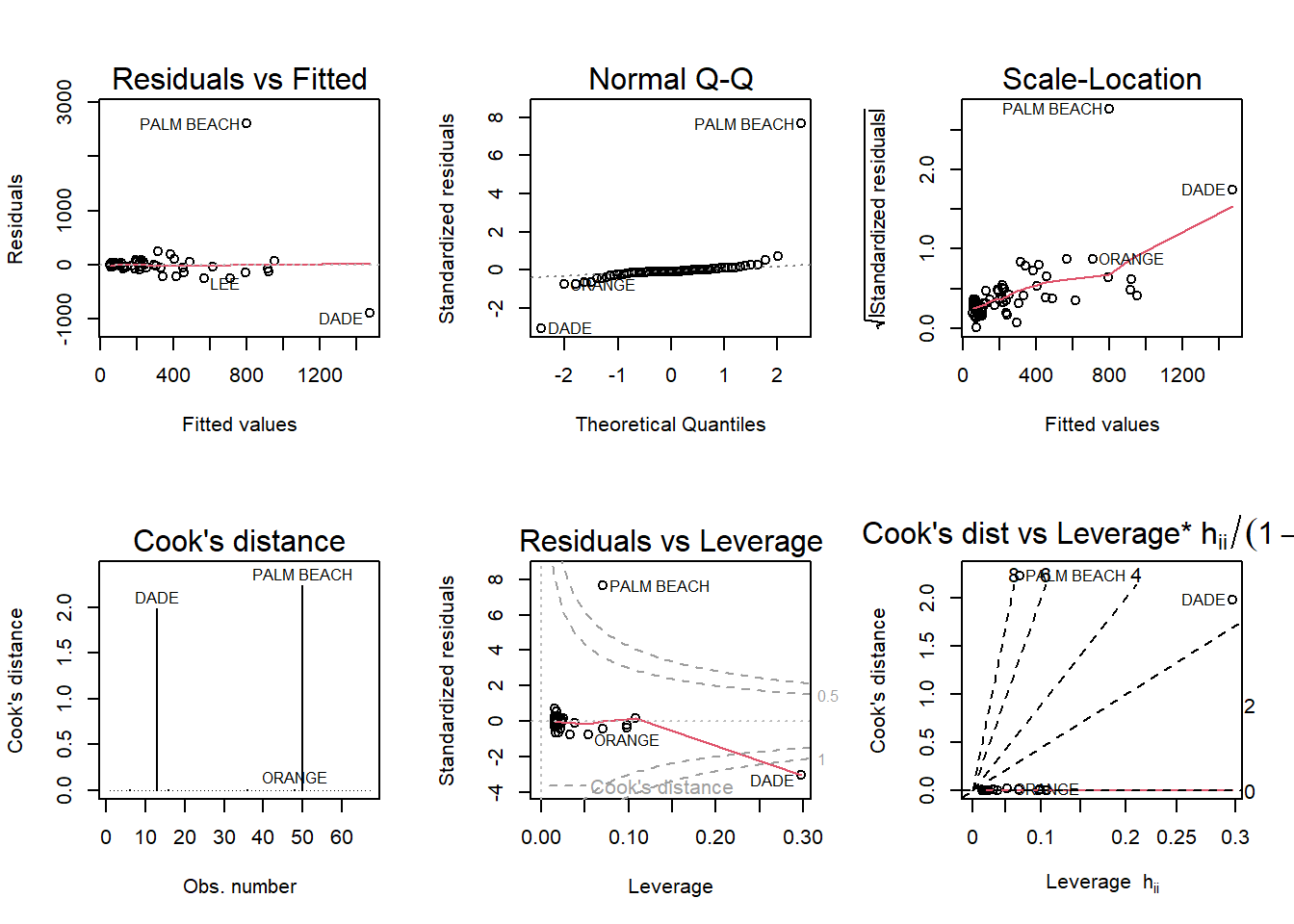
Run a simple linear regression model where the Buchanan vote is the outcome and the Bush vote is the explanatory variable. Produce the regression diagnostic plots. Is Palm Beach County an outlier based on the diagnostic plots? Why or why not?
Code
vote <-lm(Buchanan ~ Bush, data=florida)par(mfrow =c(2,3)); plot(vote, which =1:6)
Yes, Palm Beach does appear to be an outlier on the plots. It falls outside the line of best fit in all the plots.
Part B
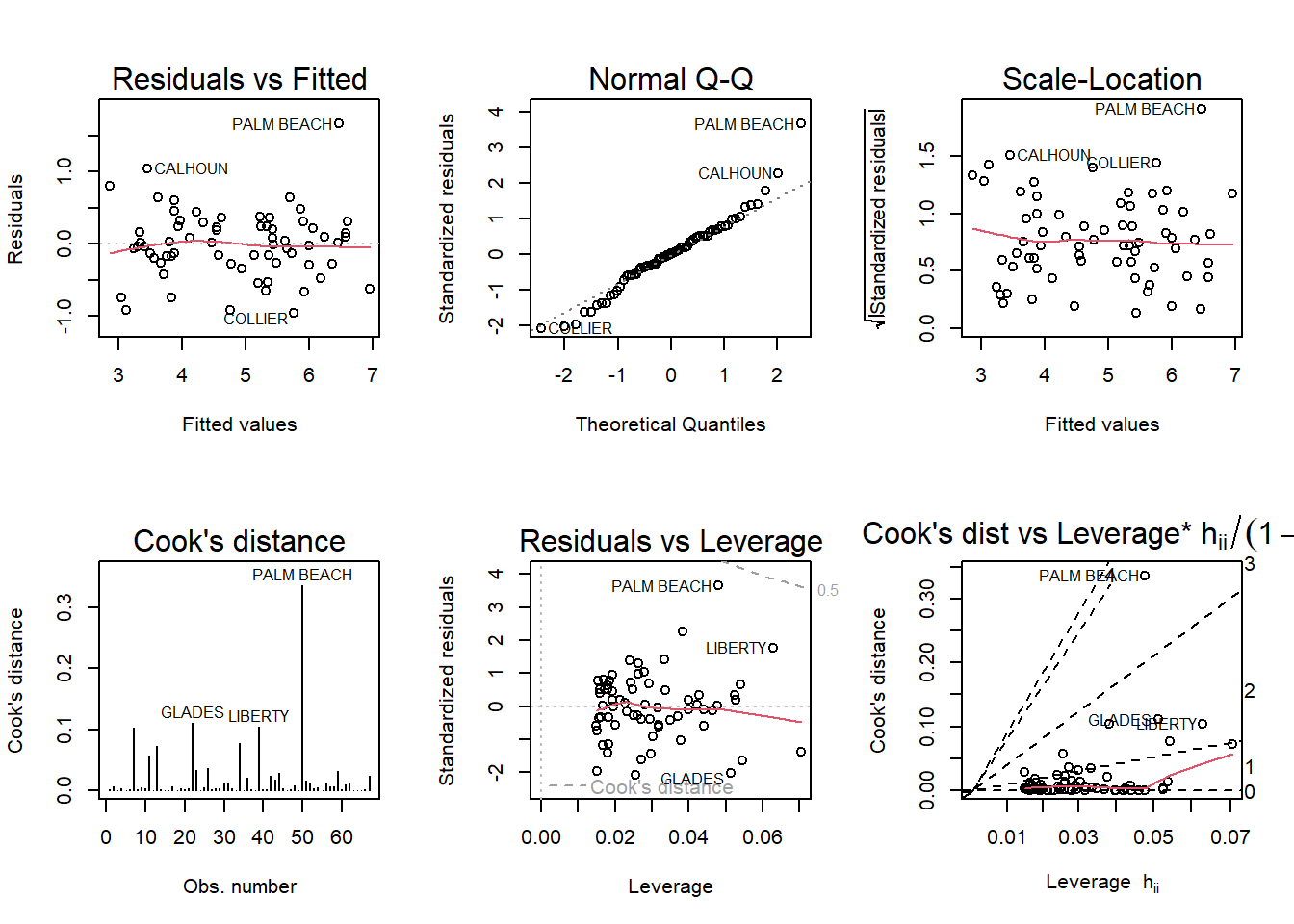
Take the log of both variables (Bush vote and Buchanan Vote) and repeat the analysis in (a). Does your findings change?
Code
vote_log <-lm(log(Buchanan)~log(Bush),data=florida)par(mfrow =c(2,3)); plot(vote_log, which =1:6)
Palm Beach is still an outlier, but additional counties appear as outliers in several plots, such as Calhoun and Liberty.
Source Code
---title: "Homework 5"author: "Emily Duryea"desription: "Final Project Proposal"date: "12/09/2022"format: html: toc: true code-fold: true code-copy: true code-tools: truecategories: - Emily Duryea - hw5 - homework5---# Homework 5```{r}library(alr4)library(smss)library(stargazer)library(tidyverse)```## Question 1```{r}data(house.selling.price.2)summary(lm(P ~ ., data = house.selling.price.2))```### Part AQuestion: For backward elimination, which variable would be deleted first? Why?Answer: For backward elimination, the first variable to be deleted would be the beds variable, as it is the weakest indicator with the highest p-value (0.486763) in the regression analysis.### Part BQuestion: For forward selection, which variable would be added first? Why?Answer: For forward selection, the first variable to be added would be size, as it has the highest t-value (11.504) in the regression analysis.### Part CQuestion: Why do you think that BEDS has such a large P-value in the multiple regression model, even though it has a substantial correlation with PRICE?Answer: I think that the beds variable is not statistically significant, which has little to do with the correlation (correlation does not equal causation). There could be another, stronger indicator that is influencing the high correlation with price, such as the size of the house.### Part DQuestion: Using software with these four predictors, find the model that would be selected using each criterion:#### Part 1: R2```{r}m1 <-lm(P ~ S, house.selling.price.2)stargazer(m1, type ='text')m2 <-lm(P ~ Be, house.selling.price.2)stargazer(m2, type ='text')m3 <-lm(P ~ Ba, house.selling.price.2)stargazer(m3, type ='text')m4 <-lm(P ~ New, house.selling.price.2)stargazer(m4, type ='text')m5 <-lm(P~., house.selling.price.2)stargazer(m5, type ='text')m6 <-lm(P~.-Be, house.selling.price.2)stargazer(m6, type ='text')```m1 = 0.808m2 = 0.348m3 = 0.509m4 = 0.127m5 = 0.869m6 = 0.868#### Part 2: Adjusted R2m1 = 0.806m2 = 0.341m3 = 0.504m4 = 0.118m5 = 0.863m6 = 0.864#### Part 3: PRESS```{r}PRESS <-function(linear.model) { pr <-residuals(linear.model)/(1-lm.influence(linear.model)$hat) PRESS <-sum(pr^2)return(PRESS)}cat(' ', 'PRESS', '\n','m1: ', PRESS(m1), '\n','m2: ', PRESS(m2), '\n','m3: ', PRESS(m3), '\n','m4: ', PRESS(m4), '\n','m5: ', PRESS(m5), '\n','m6: ', PRESS(m6), '\n')```m1 = 38203.29m2 = 122984.3m3 = 95732.14m4 = 164039.3m5 = 28390.22m6 = 27860.05#### Part 4: AIC```{r}cat(' ', 'AIC', '\n','m1: ', AIC(m1), '\n','m2: ', AIC(m2), '\n','m3: ', AIC(m3), '\n','m4: ', AIC(m4), '\n','m5: ', AIC(m5), '\n','m6: ', AIC(m6), '\n')```m1 = 820.1439m2 = 933.7168m3 = 907.3327m4 = 960.908m5 = 790.6225m6 = 789.1366#### Part 5: BIC```{r}cat(' ', 'BIC', '\n','m1: ', BIC(m1), '\n','m2: ', BIC(m2), '\n','m3: ', BIC(m3), '\n','m4: ', BIC(m4), '\n','m5: ', BIC(m5), '\n','m6: ', BIC(m6), '\n')```m1 = 827.7417m2 = 941.3146m3 = 914.9305m4 = 968.5058m5 = 805.8181m6 = 801.7996### Part EQuestion: Explain which model you prefer and why.Answer: The model that I prefer would be m6, which includes all variables but the beds variable. It was the best fit model in most of the tests. A second choice would be m5, which includes all variables, as it also performed similarly to m6.## Question 2### Part AFit a multiple regression model with the Volume as the outcome and Girth and Height as the explanatory variables.```{r}tree <-lm(Volume ~ Girth + Height, data=trees)tree```### Part BRun regression diagnostic plots on the model. Based on the plots, do you think any of the regression assumptions is violated?```{r}par(mfrow =c(2,3)); plot(tree, which =1:6)```Answer: In the first plot, residuals vs fitted, the assumption of linearity is violated as the line is a curved line rather than linear. The other plot that has a violation is the scale-location plot, as it is not a horizontal line, but rather, interestingly skewed.## Question 3### Part ARun a simple linear regression model where the Buchanan vote is the outcome and the Bush vote is the explanatory variable. Produce the regression diagnostic plots. Is Palm Beach County an outlier based on the diagnostic plots? Why or why not?```{r}vote <-lm(Buchanan ~ Bush, data=florida)par(mfrow =c(2,3)); plot(vote, which =1:6)```Yes, Palm Beach does appear to be an outlier on the plots. It falls outside the line of best fit in all the plots.### Part BTake the log of both variables (Bush vote and Buchanan Vote) and repeat the analysis in (a). Does your findings change?```{r}vote_log <-lm(log(Buchanan)~log(Bush),data=florida)par(mfrow =c(2,3)); plot(vote_log, which =1:6)```Palm Beach is still an outlier, but additional counties appear as outliers in several plots, such as Calhoun and Liberty.